Published 2019-04-02; Last modified 2019-04-08
Jonathan Hennessy-Doyle
The Horseshoe Lifecycle of A/B Testing
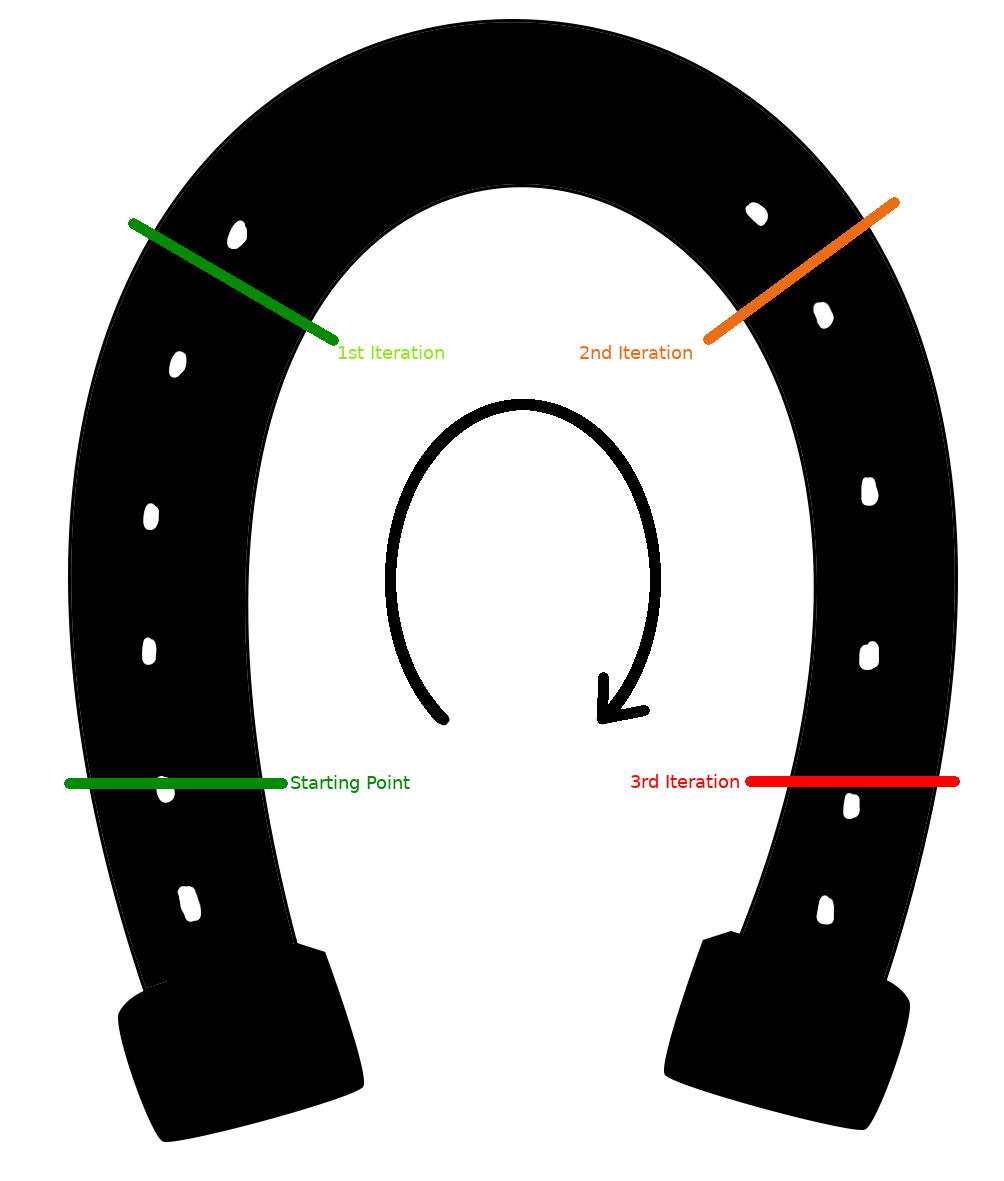
Twice I’ve noticed a curious effect when I was running A/B tests where overall performance was not increasing as I expected, even when each individual iteration was telling me that it should. I’ve drawn this effect in this handy image.
Where did this concept come from?
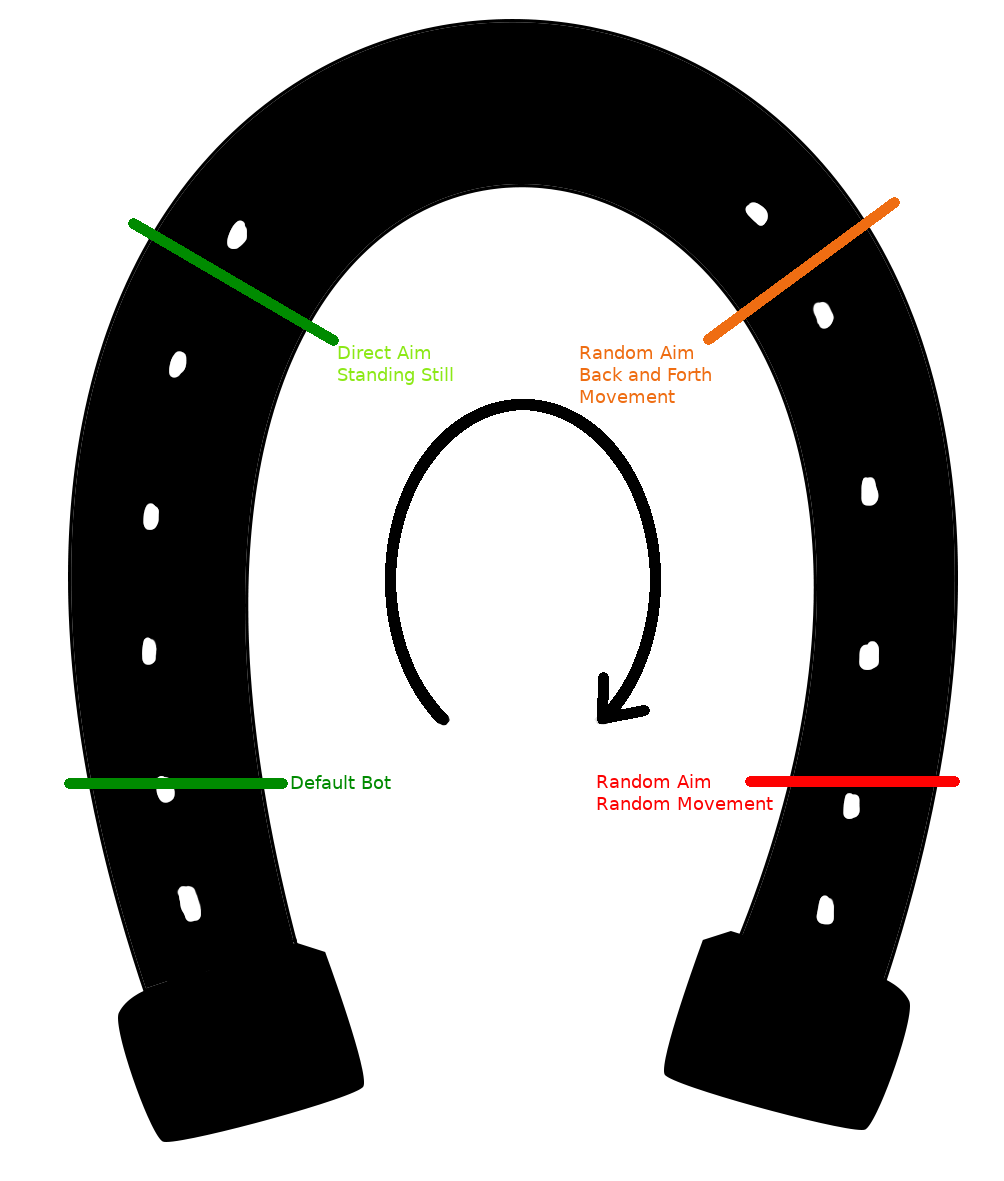
Let me bring you back to what first made me think about this lifecycle: Robocode, a simple programming game where you control a robot tank and tell it how to defeat the other robot tanks. There are two primary controls, movement and shooting the gun.
The default bot takes a very simple approach, it stays still and shoots at exactly where its opponent currently is. When I wrote my first bot I started by copying the behaviour of the default bot and testing my new bot against the default one. The first iteration I wrote changed the movement code to move back and forth in a straight line. Because of how the bots were placed at match start this simple movement avoided every shot from the default bot; it also hit every shot it fired, resulting in a quick win. Feeling very happy with myself I continued iterating my bot, testing each new version against its predecessor until it would reliably win. The next iteration had to hit this bot during its back-and-forth movement. Not having any idea how to properly calculate how to account for this I resorted to randomly aiming the gun vagely near the target while keeping the back-and-forth movement. This would work, as it would never be hit itself but sometimes (<1/20) hit its opponent, and so it became the new baseline and I made another iteration. After a few evenings of iterating this I ended up with a bot with essentially random shooting and near-random arc movement. For kicks I decided the pair it against 8 of the default bots to see I it would win. It didn’t, my latest version lost every round against the default bot, even down to 1v1. Turns out the default bot could hit whenever an arc movement of the latest bot was roughly in a straight line to or from it, while the latest bot, tested only against a bot that never stood still, would never hit it back.
What happened?
The simplest explanation is that each bot was simple overfitting to the previous bot, and wasn’t given a test set with a wide variety of behaviours to learn against. However, years later at work I noticed that my A/B testing improvements to a long running system were not doing much better than historical versions, and I realised that I might have fallen into the same trap as in my old Robocode days. With the benefit of extensive logging I could compare the A and B candidates against the whole history of the system, but it made got me thinking about what could be happening with projects that weren’t as logged as mine. After working through how more effort was causing the end performance to wrap around to be equal to, or even below, the performance of the original I realised that it resembled a horseshoe, returning to where it began but not quite touching.
So how could this happen to me?
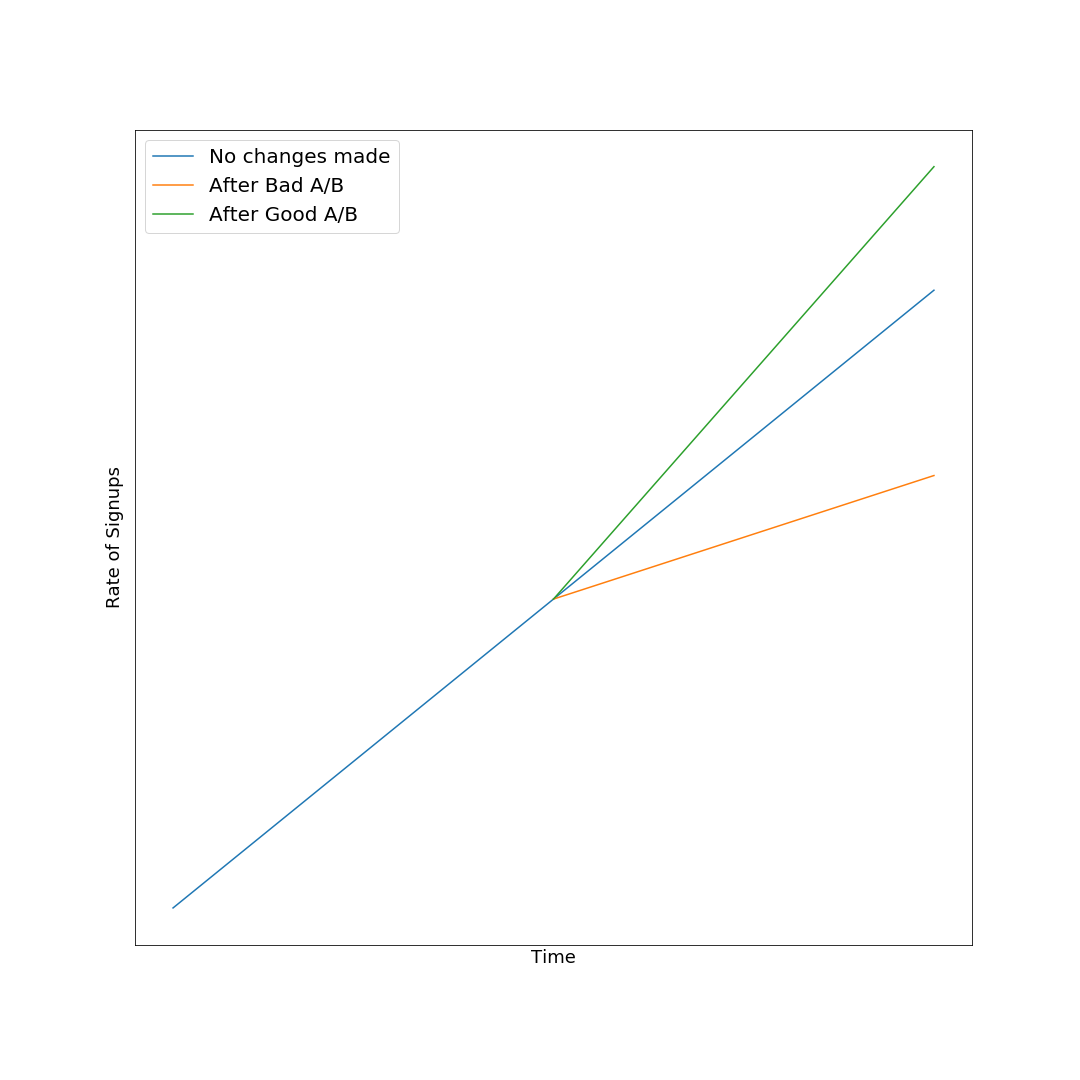
It might seem that this effect hasn’t or couldn’t happen with your A/B testing for your system. After all, you’ve been careful to follow best practices for your testing and have the data to prove that your new version has better KPI/signups/etc. So where could you go wrong? Let’s take signups as an example. You’ve been A/B testing since guiding you’re first customer through the process. Every step of the way you’ve been A/B testing you signup story to increase throughput, and every step of the way you have data to show that you’re new A has N% higher follow through than the old B. That’s the catch, better than the one before, not better than everything that came before. A and B were both tested against your most recent signups, you don’t know whether version H from 6 months ago would have done even better with those same prospective customers. It’s entirely possible that you’ve gotten really, really good at targeting one demographic while gradually excluding all of the other potential candidates.
So how can I avoid this problem?
I believe that all binary A/B testing will eventually hit this lifecycle problem. The ideal solution is to run an A/Rest test against all past versions, guaranteeing that you pick the best version for your metric. This has a obvious major problem however, you don’t have anywhere near the resources or opportunities to run a test with everything you’ve ever built, so you’ll need to compromise. I’ve had good success with adding a third option to the test, a randomly selected ~6 month old production version. In my testing this has avoided horseshoeing while also delivering an iteration with the metric improvements I was originally looking for.